


I thought I’d do a quick little post on how to use FDM mapping tables to your advantage. To do this, I am taking advantage of the backend SQL tables that support FDM. I was recently given a scenario where I needed to use data mappings to load data into an Essbase reporting application. The environment had Essbase (for reporting), Planning, FDM and HFM. All products were on version 11.1.2.2. FDM (not of the EE persuasion) was used to load data into HFM.
The issue came up when we needed to load trial balance data from a newly acquired business, operating on one chart of accounts, to the head office, operating on a different chart.
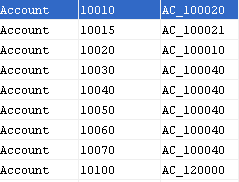
To illustrate, a sample record may look like this:
![]()
In other words, the source data contained members which did not exist on the Essbase side. So, we needed to map records for these intersections into the correct counterparts on the Essbase side. Now, we could use different kinds of techniques to achieve this mapping, including, but definitely not limited to:
- “Replace” functionality on load rules
- SQL mapping tables, among others
But the problem still remains as to how to expose these mappings to users so that they could make additions, make changes or even just see how the target data was sourced? I didn’t want them to have to update tables or rules, but at the same time, wanted a more dynamic way to maintain these mappings.
Since we already had an FDM application feeding HFM, I decided to use this existing application as the repository for the mapping information. Users are used to updating maps for HFM anyways, and this would be no different and honestly, I did not want to create a new application to load into Essbase. I am quite happy with load rules. The architecture I had in mind would look a bit like this:
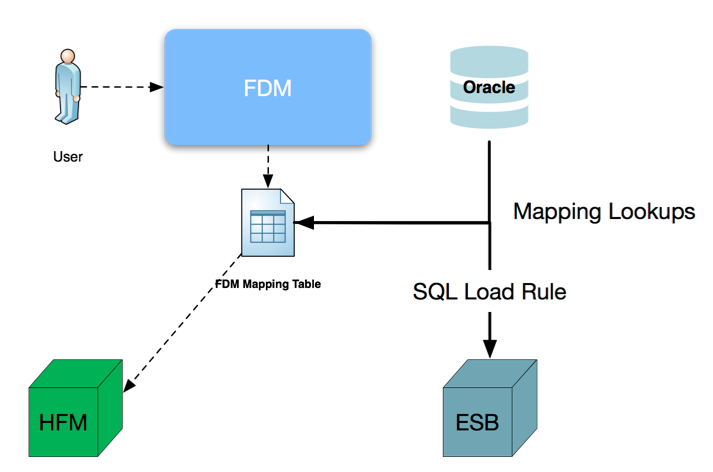
Steps:
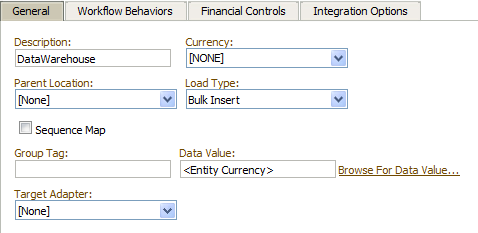
- Set up a “mapping” location not tied to any import format.
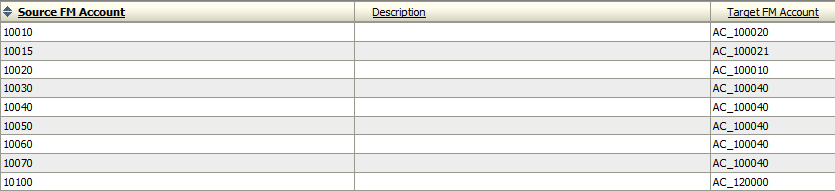
- Create maps tied to the location above. I created maps for all the dimensions in question.
- Set up a simple view on the FDM schema to generate the source and target lookups. The schema contains a number of tables, but I only needed 2, TDATAMAP and TPOVPARTITION.
TPOVPARTITION contains the names of the locations and the “key” (PARTITIONKEY column) to join to the TDATAMAP table.
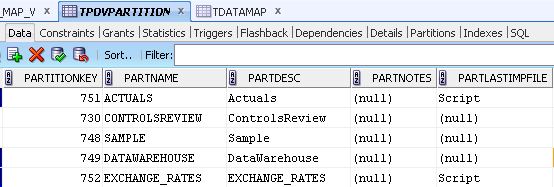
TDATAMAP contains all the mappings.
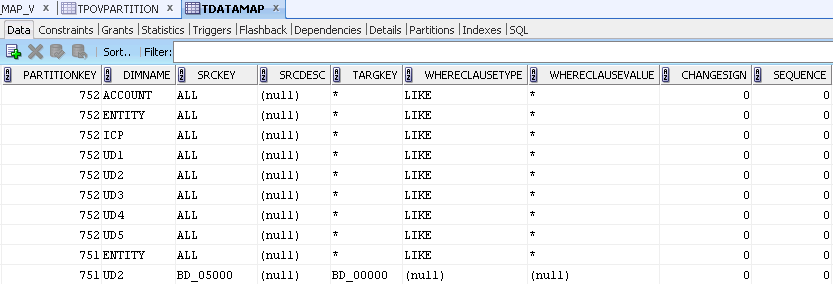
The DIMNAME column can be used to figure out the name of the source dimension. For instance, account and entity dimensions will have explicit names of ACCOUNT and ENTITY respectively. The other dimensions are referred to as UD1, UD2 etc. It isn’t hard to figure out which dimension is which.
The query below gives me the details that I needed for my purposes:
select decode(map.dimname, 'UD1', 'Dept', -- get the right dimension name
'UD2', 'Product',
'UD3', 'Other',
'UD4', 'CashFlow',
'UD5', 'Check',
'ACCOUNT', 'Account',
'ENTITY', 'Entity') DIM_NAME,
map.srckey SRC_VAL,
map.targkey TARG_VAL
from tdatamap map,
tpovpartition mapname
where map.partitionkey = mapname.partitionkey -- join the 2 tables
and map.whereclausetype is null -- explicit mappings only
and mapname.partname = 'DATAWAREHOUSE'; -- FDM location name
- Set up a SQL load rule to load data into Essbase with lookups to the mapping view above. I am not going to go into the details of that exercise. The only other configuration I needed to make this work, was to make sure the Oracle schema for loading data could “see” and query the FDM schema. The DBA helped set this link up.
Conclusion
There are a number of uses I can think of for this type of load mechanism. You could use the mapping tables to further perform drill through from the primary chart of accounts, to the secondary chart. You are also empowering your users to maintain these mappings.
One last note, I haven’t had the opportunity to test this on any version post 11.1.2.2 or on Enterprise Edition.
Thanks to Koti C. for providing the initial input on which FDM tables might be of use.