


My last post was almost a year ago. I have been tied up on pretty large projects and never got a chance to find time to share some more insights on the daily issues we may encounter.
I have been trying to stay away from the cloud as I felt it wasn’t quite there yet compared to on premises solutions but after a year in London and now back states side, I actually wanted to start working on it especially EPBCS due to the very interesting possibilities that Groovy can provide.
So I finally got assigned to a PBCS project – no groovy for me for now 🙁 – which isn’t a problem. At least I get to learn the basics of PBCS and its limitations compared to the on Premises solution. (there are a few…) Here are a couple examples… a) there is no way (at this time, as far as i know) to take a simple level 0 backup of a cube (The Export Data feature is fine if you have a small data set in your cube but not quite there yet to export an entire live cube) b) the Export Data feature for exporting specific data set is very user friendly but the performance isn’t there (Thankfully we can still use the old DATAEXPORT command as detailed on a few blog posts)
Anyway, what I wanted to cover in this post was an issue my current client was having i.e. they have been live for over a year and their monthly actuals load (~10 million records with one data column) is now taking between 3 and 4 hours but it was taking about 20 minutes with the same method when they first went live.
It may have been covered on some other blog posts but I couldn’t find anything for PBCS/EPBCS newbies like me that explained what was the best approach to loading data out of the box and whether what we know about Essbase/Planning on premises applies to PBCS?
Here are the results of what I’ve seen in my client’s case when loading the same data set in different formats (I’m not including the upload time of the file) and they are provided to give you an idea of the performance of each formats, Essbase vs Planning, 1 column vs multiple columns, sorted vs not sorted, in an empty cube vs a live cube with many years of data.
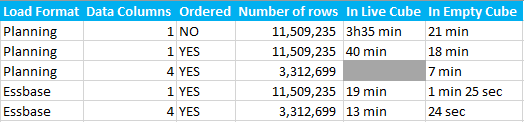
- Tested the original Planning format (csv) not ordered in an empty cube and I got the same performance as what they were experiencing when they first went live. But a year later, the same exact file is taking more than 3 hours to load in their live cube. Below is a simplified example of their file (Account, scenario and periods i.e. weeks are dense dimensions) and dimensions are not properly ordered which caused the load to take more time that it needed to as they were going through the same block more than once.
- Tested the original Planning format, but ordered this time and we saw significant improvements right away in the live cube just by reordering the dimensions and making sure that data was sorted. Note that the performance improvements are minimal in the empty cube which highlights that the ordering and sorting of the members/ dimensions has almost no impact when loading data in an empty cube.
 Next I tried to use a Planning format sorted but with Wks (period) in separate columns, i.e. Wk1, Wk2, Wk3, Wk4 (since we are loading a full month at once) – this led to the number of rows to shrink to 3.3 million rows instead of 11 millions. In this case I only tried in the empty cube and in this case the load time was cut by more than half.
Next I tried to use a Planning format sorted but with Wks (period) in separate columns, i.e. Wk1, Wk2, Wk3, Wk4 (since we are loading a full month at once) – this led to the number of rows to shrink to 3.3 million rows instead of 11 millions. In this case I only tried in the empty cube and in this case the load time was cut by more than half.- Then I started to use the Essbase format, a tab delimited txt file, first with one column. In this case all dimensions are represented on each row (no header needed) and this time I saw another huge performance improvement. Load time was divided by 2 in the live cube compared to the Planning format sorted with 1 data column while the load time was divided by almost 5 in the empty cube.
 Finally, I tried the Essbase format, still tab delimited with a data column for each week. In this case you will need the header with one member for each data column (The header doesn’t need to be aligned with the data columns themselves as show in the below screenshot) and this time we saw another significant performance improvement. In the empty cube we are now down to 25 seconds to load 11 millions cells, and 13 minutes in the live cube.
Finally, I tried the Essbase format, still tab delimited with a data column for each week. In this case you will need the header with one member for each data column (The header doesn’t need to be aligned with the data columns themselves as show in the below screenshot) and this time we saw another significant performance improvement. In the empty cube we are now down to 25 seconds to load 11 millions cells, and 13 minutes in the live cube.
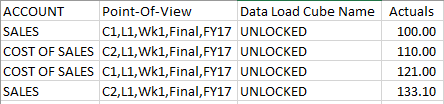
 Know though that at this time there seem to be an issue with the Essbase format with multiple columns. The data in the above would work fine as no data cells are null/empty but if we take the 3rd row in the below data file, you will notice that Wk1 has no data
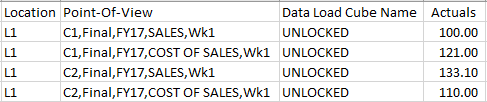
Know though that at this time there seem to be an issue with the Essbase format with multiple columns. The data in the above would work fine as no data cells are null/empty but if we take the 3rd row in the below data file, you will notice that Wk1 has no data but once the data has been loaded, you will see that the Wk2 data has been loaded incorrectly to Wk1 instead. The Essbase format with multiple columns will shift your data to the left for rows with empty data cells.
but once the data has been loaded, you will see that the Wk2 data has been loaded incorrectly to Wk1 instead. The Essbase format with multiple columns will shift your data to the left for rows with empty data cells. I have opened an SR to find out whether this is expected or if it is a bug and I have been told that “The multiple data columns are not supported and the product is working as expected” so if you still want to use the Essbase format with multiple data columns then make sure to specify #MI or #Missing as in the below screenshot and the data will load in the proper intersections.
I have opened an SR to find out whether this is expected or if it is a bug and I have been told that “The multiple data columns are not supported and the product is working as expected” so if you still want to use the Essbase format with multiple data columns then make sure to specify #MI or #Missing as in the below screenshot and the data will load in the proper intersections.

So the main take away from this post is that if you don’t have to use a planning format (due to having to load text mainly), you should follow the same assumptions as in an on premises solution:
- you should use the Essbase format
- make sure to order your records by block, so that during the load, you don’t have to go through the same block more than once or it will affect your performance (maybe not at first but in the long run you will as shown)
- try to have multiple data columns (from a dense dimension like Period) but make sure to use #MI for empty cells or once loaded, data will be shifted to the left.
Hopefully this helps.
Will, is that really load time or upload + load? Did you try zipping the file and then load?
Hi – No I’m talking about pure load time once the file is uploaded to the Inbox/Outbox folder as a csv file for the Planning format or txt file for the Essbase format. Have you noticed better load time if the file is zipped?
Will – that’s really interesting thanks.
Do you have the ability to select to use the essbase load function in Data Management as well? Or is it purely through the Planning connector these days?
Thanks Peter! Regarding your question, I don’t know. I’m just starting with the cloud and I haven’t looked at Data Management yet. This post was just about the out of the box Import Data feature.