


I thought today we’d take a look at whether it would be possible to do an entire post on record separators, and how they apply to ODI! Be still, my beating heart! Yes, this has all the potential of being one of the most exciting posts I’ve put up. So anyways, let’s get to it. One of the most common things we do in Essbase, is to create data export scripts, to export out data from our cubes. With the script below, I am generating a tab-delimited export file.

It generates a file like this:

One of the other common things to do, is to use ODI to maybe load this file into a table. To do this, we just “reverse” the file, and set up a model within ODI. I should also mention that all technologies mentioned on this post, are on Windows operating systems. It looks like I’ve set everything up properly:
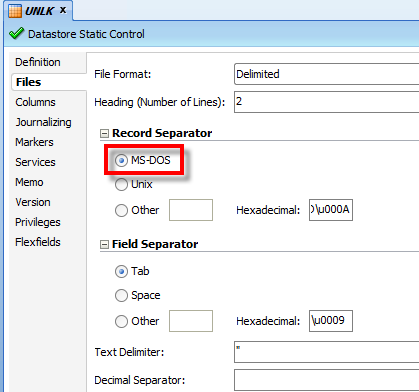
I try to reverse it, and…
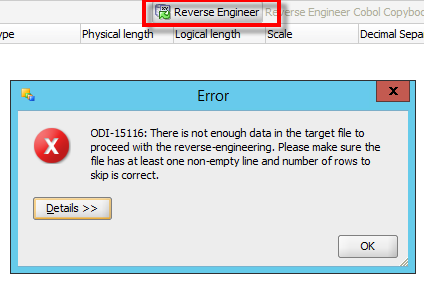
…we get the “15116” error. We know there’s data in the file, so, what gives? The answer, is to take a look at the file itself. And by that, I mean, by using a proper text editor, like Notepad++. Notepad++ allows you to look at delimiters, and any other gremlins on the file. Let’s change our view to show all symbols.
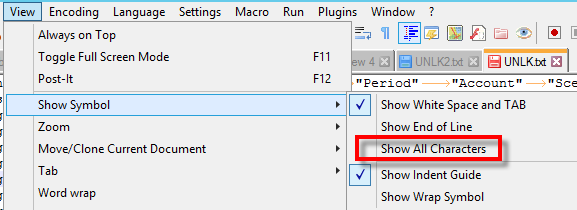
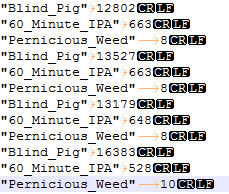
Our file now shows all characters and we can see a new character, “LF”.
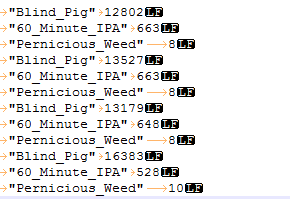
“LF” refers to “Line Feed”. Wiki also tells us that “LF” is reserved for Unix operating systems, and “Carriage Return + LF”, for Windows. For whatever reason, the Essbase data export seems to be using “LF” as a record separator.

We can convert the file to “CR+LF”, by doing a replace on Notepad++.
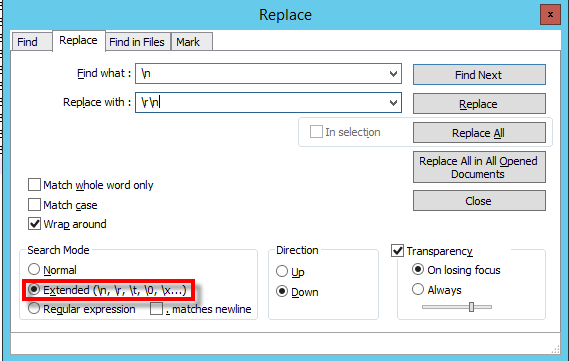
This should let us reverse successfully on ODI. While this will work, we can also just change the record separator, to “Unix”, as a long term solution.
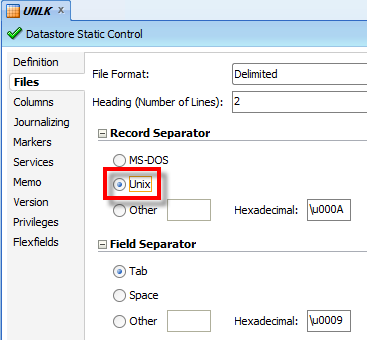
Perform the reverse again, and Bob’s your uncle.
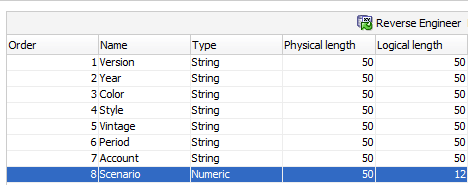
And there you have it, an epic, ground-breaking write-up on investigating the record separator. Nuff said.
Hi Vijay ,
I have a small query in DRM.what role does Pagefile Drive plays in DRM server ?
Regards
Di
Hello,
I do not have a good answer for this, other than the fact that it works as an extension of your RAM…helping move objects in and out of RAM to free up memory.
Hello Vijay,
Need some info regarding DRM, What role does pagefile drive plays in DRM server ?
Regards
Di